
In this blog we will understand how to use Tensoflow for Linear and Logistic Regression. I hope you have read 1st blog of this series, if not please give it a read.
Why in the world would I use Tensorflow for regression?
No. you will not. Though to understand each function of Tensorflow properly I suggest you go through this.
Linear Regression
Start with generating the data.
|
|
Equation of Y in terms of X_data
|
|
Now, to start with we need to define Place holders for the data feeding while training. We have seen what placeholders do in the last blog.
|
|
Here shape is [None, 4]. What does this mean? It means we can provide any value in place of None. So while feeding we can provide as many examples we want. This is very useful in mini batch training, which we will see in the subsequent blogs. So, basically we feed training data through placeholders.
Now we will define weight variable and intercept term. This will be tf.Variable because we need to find the value of W and b. So, we will initialize it randomly and then using optimization algorithm we will reach to the true value.
|
|
Next we generate our hypothesis. Read more about more matrix functions like matmul here.
|
|
Now we will define our loss function. We will be using RMSE (reduced mean squared error) loss.
|
|
Next we will use Stochastic Gradient Optimizer to minimize this loss. If you don’t know how this optimization is carried out, I strongly suggest you to read this great blog on gradient descent optimization.
|
|
Now as we’ve seen in previous blog, tensorflow is Static graph. We need to start Tensorflow session to pass data through this graph.
|
|
Now everything is set. We need to feed data to the graph and find the optimal values for W and b

Now here you need to understand what sess.run() does? It basically computes the values of the quantities you specified (in our case Loss, hypothesis, W, b, train). But look train is not a quantity, it’s just an optimizer trying to minimize error. So, based on the current error when you run train, it will update values of W and b. This will continue for all 20000 epochs.
As you can see at the end W and b values are very close to its original values.
You can find a full code here.
Logistic Regression
We will use iris data for logistic regression. Iris data has three classes (setosa, versicolor and virginica). I used setosa as class “0” and versicolor and virginica as class “1”.
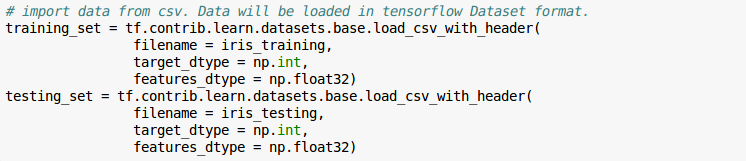
Here is how you import data using tensorflow. We have two files iris_training.csv and iris_test.csv
|
|
Now to import data from these csv. More about reading data in tensorflow here.
Now logistic regression is useful can do binary classification only! So, we need to merge two classes.
|
|
Again it’s the same as before. Define placeholders, variables, Hypothesis, Loss function and Optimizer.
|
|
This all steps are self explaining. Here loss in categorical cross entropy loss, you can read about it here
If hypothesis value is > 0.5, class ‘1’ otherwise class 0. And accuracy is simple classification accuracy.
|
|
Let’s train:
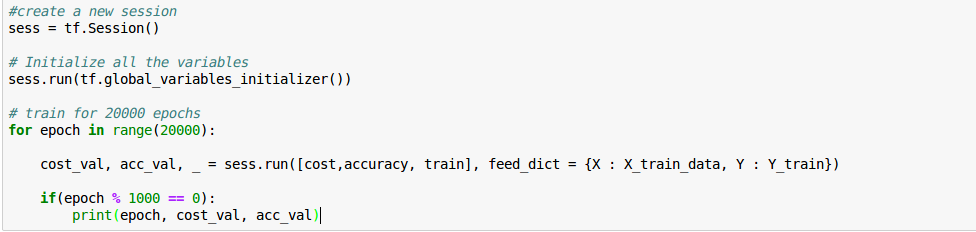
Check the accuracy on test data. It is about 0.73
|
|
Let’s check the result with sklearn Logistic Regression
|
|
Both accuracies are comparable, but sklearn is surprisingly fast. I have to look into it.
In my full code here, I have even tried regularization at the end, but it didn’t improve accuracy.
REFERENCES:
Note: I strongly suggest to go deep into references. Whatever I’ve written here is just to make you feel comfortable with tensorflow, but all the magics lie in References.
Happy learning! :D
Hit ❤ if this was useful.