It’s time to give the Algorithm series, an informative start. Here, we start with one of the most famous category i.e. Tree Based Models, which consists of Decision Trees, Random Forest and Boosting methods.
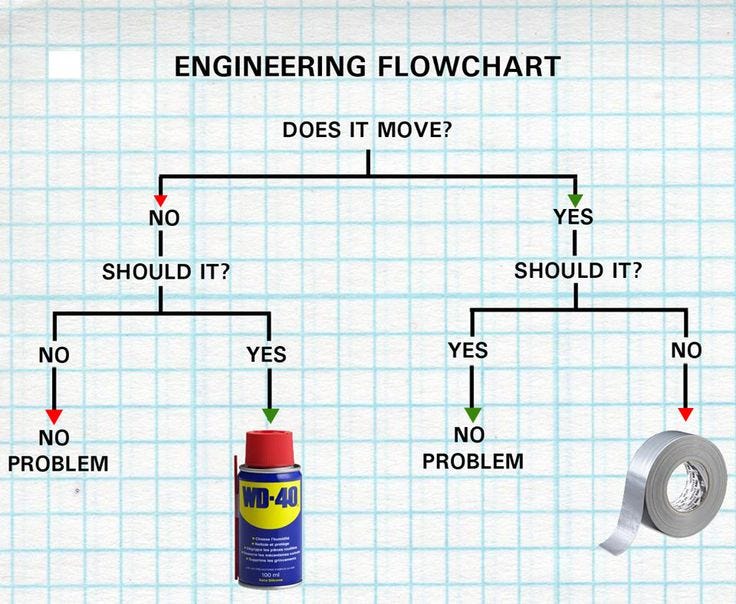
To initiate the learning with a basic example, the above is a decision tree for you:
Yes, you may be thinking that ML can’t be this easy. Frankly, it is. Trust me.
A river cuts through a rock not because of it’s power, but it’s persistence.
What is a Decision Tree?
As the name says all about it, it is a tree which helps us by assisting us in decision-making. Used for both classification and regression, it is a very basic and important predictive learning algorithm.
-
It is different from others because it works intuitively i.e., taking decisions one-by-one.
-
Non-parametric: Fast and efficient.
It consists of nodes which have parent-child relationships:
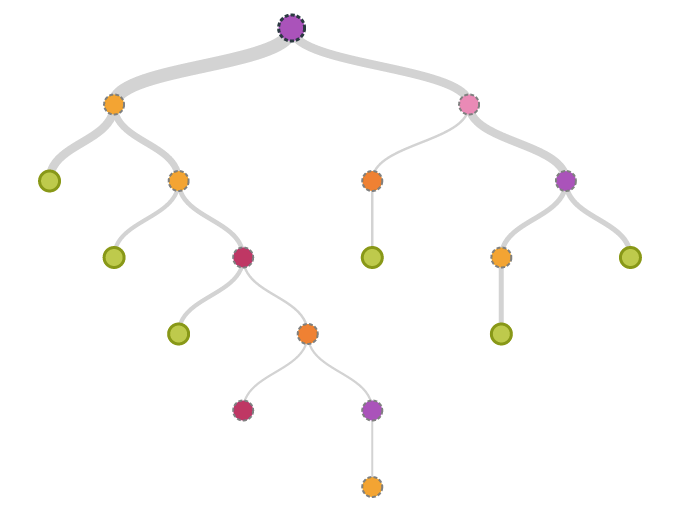
Finally, it gives us what we actually want - prediction for a given scenario.
How it works?
It breaks a dataset into smaller subsets, and at the same time, an associated decision tree is incrementally developed. As it happens in real life, we consider the most important factor, and divide possibilities according to it. Similarly, tree building starts by finding the variable/feature for best split.
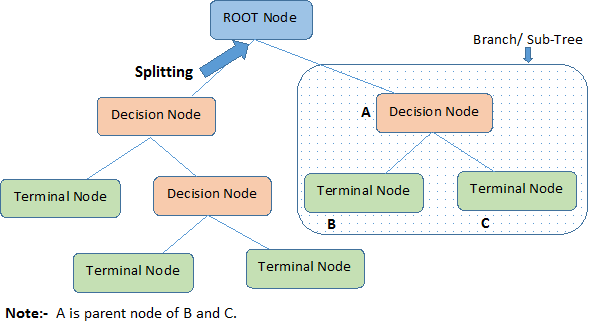
First of all, let’s cover the basic terminology used:
-
**Root Node: **Entire population or sample, further gets divided into two or more homogeneous sets.
-
Parent and Child Node: Node which is divided into sub-nodes is called parent node, whereas sub-nodes are the child of parent node.
-
Splitting: Process of dividing a node into two or more sub-nodes.
-
Decision Node: A sub-node that splits into further sub-nodes.
-
**Leaf/ Terminal Node: **Nodes that do not split.
-
**Pruning: **When we remove sub-nodes of a decision node, this process is called pruning. (Opposite of Splitting)
-
Branch/Sub-Tree: Sub-section of entire tree.
Splitting! What is it?
Decision tree considers the most important variable using some fancy criterion and splits dataset based on it. It is done to reach a stage where we have homogenous subsets that are giving predictions with utmost surety.

These criteria affect the way tree grows, and thus the accuracy of model. It takes place until a user-defined stopping condition is reached, or perfect homogeneity is obtained.
To put things in perspective, check out how **Airbnb** improved their accuracy using new confidence splitting criteria.
Some of them are:
-
Gini Index: Measure of variance across all classes of the data. Measures the impurity of the data. Ex. Given a binary classification problem, the number of positive cases equals the negative ones. GI = 1/2(1–1/2)+1/2(1–1/2) = 1/2 **This is maximum GI possible. As we split data, and move towards subtree, GI decreases to zero with increase in depth of tree.
-
Entropy: Measure of randomness. More the random data, higher the entropy. **E = -p*log(p) **; p - probability
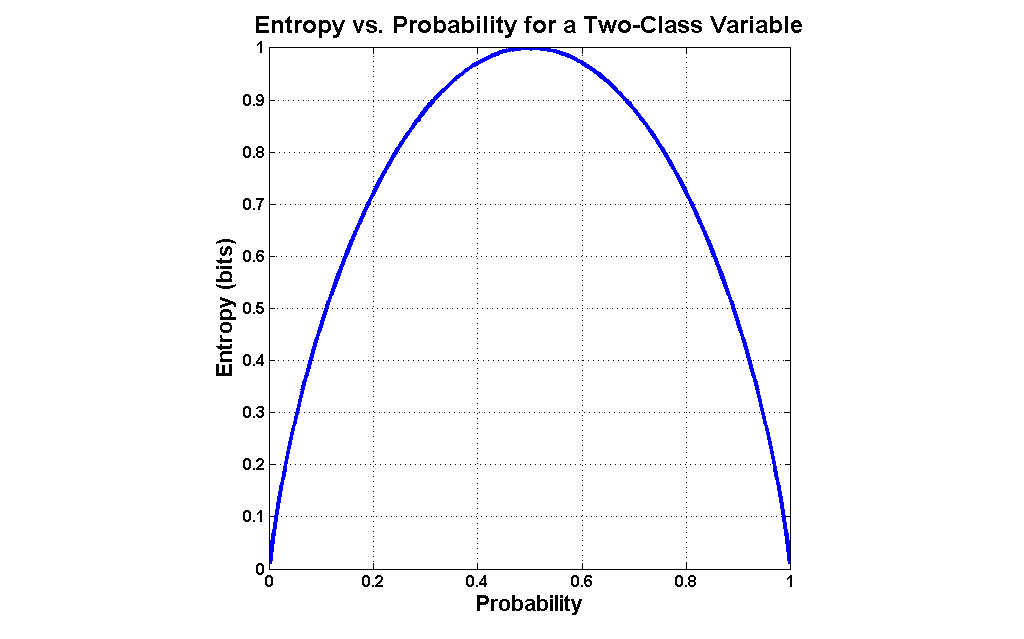
Information Gain: Decrease in entropy. The difference between the entropy before the split and the average entropy after split is obtained to decide when to split.
The variable which provides maximum entropy gain is chosen!
- **Reduction in Variance: **This is used mainly in Regression. As the name suggests, variation before split and after split is calculated. The split giving the highest reduction is selected!
Pruning of a Tree
The greed to fit data using decision tree can sometimes result in **overfitting of data. To avoid this, either strong stopping criterion or pruning is used.
Pruning is exact opposite of splitting.
-
Top down approach (early stopping)
-
Bottom up approach (error rate)
Decision tree with only one level are termed as decision stumps. Often in bagging and boosting models, to avoid overfitting, decision stump is better than full grown tree.
Is it really that good?
We have been reading about a primitive algorithm for the past 4 minutes. Let’s try to conclude whether it is worth all the attention!
Pros
-
Not every relation is linear. Non-linear relations are captured by DTs.
-
Easy to understand and visualise.
-
Can be used for feature engineering. (Ex. Binning, EDA or this)
-
No Assumptions - God Level. _/_
-
Very little data preparation needed for algorithm.
-
Model validation using statistical test, influences model reliability.
Cons
-
If not tuned well, may lead to overfitting.
-
Non-parametric, no optimisation. But, hyperparameter tuning. So, once it gives limit you can not go further.
-
Unstable. Small variation in data -> completely different tree formation.
-
In case of imbalanced dataset, decision trees are biased. However, by using proper splitting criteria, this issue can be resolved.
Most Important Parameters
Half of you must be already sleeping by now. I know it’s getting long, but such is the vastness of this algorithm. To make it easy, here are SOME important ones which you should tune to top LB:
(a) Minimum Samples Split: Minimum number of sample required to split a node. This parameter helps in reducing overfitting. High value: Underfitting, Low value: Overfitting
(b) Maximum Depth of a Tree: Most influential parameter. Gives limit on vertical depth decide upto which level pruning is required. Higher value: Overfitting, Lower value: Underfitting
(c) Maximum Features: At each node, while splitting either we can chose best feature from pool of all the features or limited number of random features. This parameter adds a little randomness - good generalised model.
Rest are available at Sklearn, but focus on these first. :D
References
-
AV Blog on Tree Based Modeling
-
http://www.ke.tu-darmstadt.de/lehre/archiv/ws0809/mldm/dt.pdf
-
http://www.iainpardoe.com/teaching/dsc433/handouts/chapter6h.pdf
-
Sklearn tree module
Footnotes
What this blog has done is made you aware of one of the basic ML algorithm. Understand it thoroughly from the links given above, and you are good to go!
Try and follow our series for a heads up on the variety that ML entails.
Thanks for reading. :) And, ❤ if this was a good read. Enjoy!
Co-Authors: Ajay Unagar, Rishabh Jain, Kanha Goyal