Introduction
Graphs
Whom are we kidding! You may skip this section if you know what graphs are.
If you are here and haven’t skipped this section, then, we assume that you are a complete beginner, you may want to read everything very carefully. We can define a graph as a picture that represents the data in an organised manner. Let’s go deep into applied graph theory. A graph (being directed or undirected) consists of a set of vertices (or nodes) denoted by V, and a set of edges denoted by E. Edges can be weighted or binary. Let’s have a look at a graph.
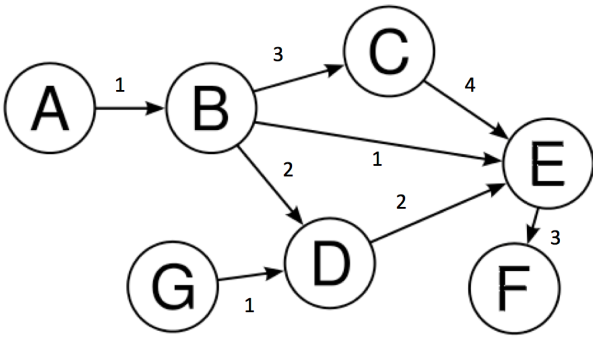
In the above graph we have:-
$$V = \{A, B, C, D, E, F, G\}$$
$$E = \{(A,B), (B,C), (C,E), (B,D), (E,F), (D,E), (B,E), (G,E)\}$$
Above all these edges, their corresponding weights have been specified. These weights can represent different quantities. For example, if we consider these nodes as different cities, edges can be the distance between these cities.
Terminology
You may skip this as well, if comfortable.

- Node : A node is an entity in the graph. Here, represented by circles in the graph.
- Edge: It is the line joining two nodes in a graph. The presence of an edge between two nodes represents the relationship between the nodes. Here, represented by straight lines in the graph.
- Degree of a vertex: The degree of a vertex V of a graph G (denoted by deg (V)) is the number of edges incident with the vertex V. As an instance consider node B, it has 3 outgoing edges and 1 incoming edge, so outdegree is 3 and indegree is 1.
- Adjacency Matrix: It is a method of representing a graph using only a square Matrix. Suppose there are N nodes in a graph, then there will be N rows and N columns in the corresponding adjacency matrix. The ith row will contain a 1 in the jth column if there is an edge between the ith and the jth node; otherwise, it will contain a 0.
Why GCNs?
So let’s get into the real deal. Looking around us, we can observe that most of the real-world datasets come in the form of graphs or networks: social networks, protein-interaction networks, the World Wide Web, etc. This makes learning on graphs an exciting problem that can solve tonnes of domain-specific tasks rendering us insightful information.
But why can’t these Graph Learning problems be solved by conventional Machine Learning/Deep Learning algorithms like CNNs? Why exactly was there a need for making a whole new class of networks?
A) To introduce a new XYZNet?
B) To publish the 'said' novelty in a top tier conference?
C) To you know what every other paper aims to achieve?
No! No! No! You see, not everything is an Alchemy :P. On that note, I’d suggest watching this talk by Ali Rahimi, which is really relevant today in the ML world.
So getting back to the topic, obviously I’m joking about these things, and surely this is a really nice contribution and GCNs are really powerful, Ok! Honestly, take the last part with a pinch of salt and remember to ask me at the end.
But I still haven’t answered the big elephant in the room. WHY?
To answer why, we first need to understand how a class of models like Convolutional Neural Networks(CNNs) work. CNN’s are really powerful, and they have the capacity to learn very high dimensional data. Say you have a $512*512$ pixel image. The dimensionality here is approximately 1 million. For 10 samples, the space becomes $10^{1,000,000}$, and CNNs have proven to work really well on such tough task settings!
But there is a catch! These data samples, like images, videos, audio, etc., where CNN models are mostly used, all have a specific compositionality, which is one of the strong assumptions we made before using CNNs.
So CNNs basically extract the compositional features and feeds them to the classifier.
What do I mean by compositionality?
The key properties of the assumption of compositionality are
- Locality
- Stationarity or Translation Invariance
- Multi-Scale: Learning Hierarchies of representations
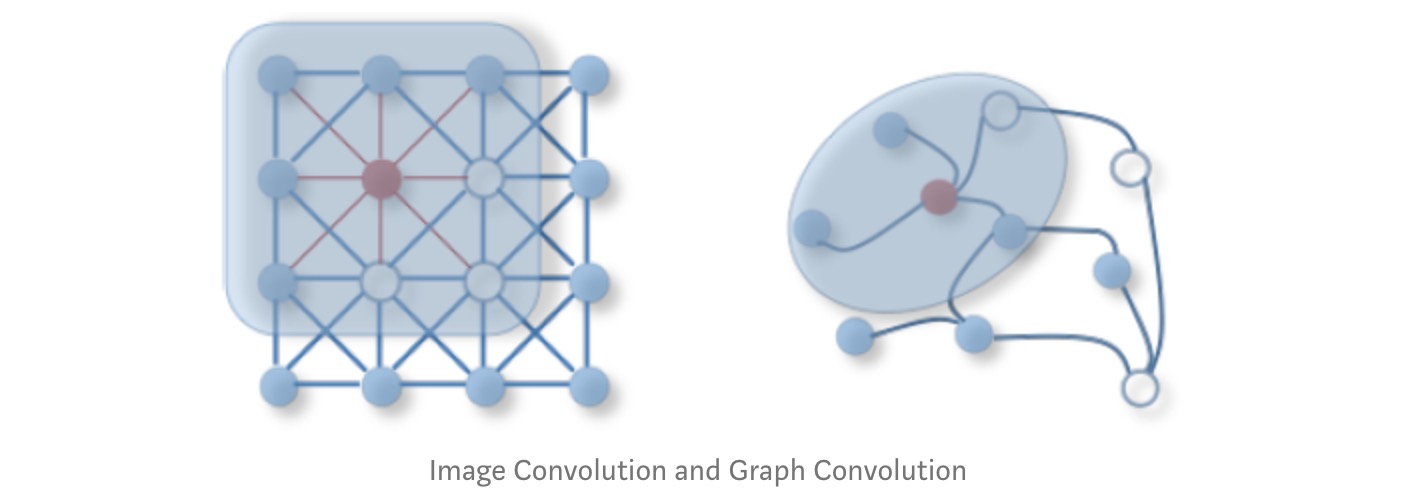
2D Convolution vs. Graph Convolution
If you haven’t figured it out, not all types of data lie on the Euclidean Space and such are the graphs data types, including manifolds, and 3D objects, thus rendering the previous 2D Convolution useless. Hence, the need for GCNs which have the ability to capture the inherent structure and topology of the given graph. Hence this blog :P.
Appllications of GCNs
One possible application of GCN is in the Facebook’s friend prediction algorithm. Consider three people A, B and C. Given that A is a friend of B, B is a friend of C. You may also have some representative information in the form of features about each person, for example, A may like movies starring Liam Neeson and in general C is a fan of genre Thriller, now you have to predict whether A is friend of C.

What GCNs?
As the name suggests, Graph Convolution Networks (GCNs), draw on the idea of Convolution Neural Networks re-defining them for the non-euclidean data domain. A regular Convolutional Neural Network used popularly for Image Recognition, captures the surrounding information of each pixel of an image. Similar to euclidean data like images, the convolution framework here aims to capture neighbourhood information for non-euclidean spaces like graph nodes.
A GCN is basically a neural network that operates on a graph. It will take a graph as an input and give some (we’ll see what exactly) meaningful output.
GCNs come in two different styles:
- Spectral GCNs: Spectral-based approaches define graph convolutions by introducing filters from the perspective of graph signal processing based on graph spectral theory.
- Spatial GCNs: Spatial-based approaches formulate graph convolutions as aggregating feature information from neighbours.
Note: Spectral approach has the limitation that all the graph samples must have the same structure, i.e. homogeneous structure. But it is a hard constraint, as most of the real-world graph data have different structure and size for different samples i.e. heterogeneous structure. The spatial approach is agnostic of the graph structure.
How GCNs?
First, let’s work this out for the Friend Prediction problem and then we will generalize the approach.
Problem Statement: You are given N people and also a graph where there is an edge between two people if they are friends. You need to predict whether two people will become friends in the future or not.
A simple graph corresponding to this problem is:

Here person $(1,2)$ are friends, similarly $(2,3), (3,4), (4,1), (5,6), (6,8), (8,7), (7,6)$ are also friends.
Now we are interested in finding out whether a given pair of people are likely to become friends in the future or not. Let’s say that the pair we are interested in is $(1,3)$, and now since they have 2 common friends, we can softly imply they have a chance of becoming friends, whereas the nodes $(1,5)$ have no friend in common, so they are less likely to become friends.
Let’s take another example:
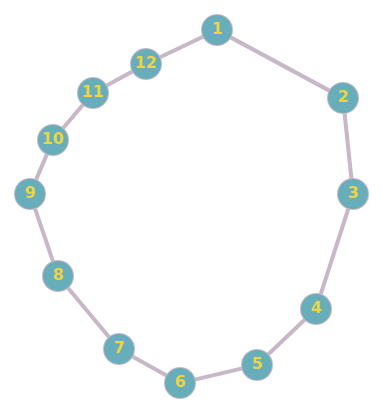
Here $(1,11)$ are much more likely to become friends than say $(3, 11)$.
Now the question that one can raise is ‘How to implement and achieve this result?’. GCN’s implement it in a way similar to CNNs. In a CNN, we apply a filter on the original image to get the representation in the next layer. Similarly, in GCN, we apply a filter which creates the next layer representation.
Mathematically we can define as follows: $$H^{i} = f(H^{i-1}, A)$$
A very simple example of $f$ maybe:
$$f(H^{i}, A) = σ(AH^{i}W^{i})$$
where
- $A$ is the $N × N$ adjacency matrix
- $X$ is the input feature matrix $N × F$, where $N$ is the number of nodes and $F$ is the number of input features for each node.
- $σ$ is the Relu activation function
- $H^{0} = X$ Each layer $H^{i}$ corresponds to an $N × F^{i}$ feature matrix where each row is a feature representation of a node.
- $f$ is the propagation rule
At each layer, these features are aggregated to form the next layer’s features using the propagation rule $f$. In this way, features become increasingly more abstract at each consecutive layer.
Yes, that is it, we already have some function to propagate information across the graphs which can be trained in a semi-supervised way. Using the GCN layer, the representation of each node (each row) is now a sum of its neighbour’s features! In other words, the layer represents each node as an aggregate of its neighbourhood.
But, Wait is it so simple?
I’ll request you to stop for a moment here and think really hard about the function we just defined.
Is that correct?
STOP
….
….
….
It is sort of! But it is not exactly what we want. If you were unable to arrive at the problem, fret not. Let’s see what exactly are the ‘problems’ (yes, more than one problem) this function might lead to:
1. The new node features $H^{i}$ are not a function of its previous representation: As you might have noticed, the aggregated representation of a node is only a function of its neighbours and does not include its own features. If not handled, this may lead to the loss of the node identity and hence rendering the feature representations useless. We can easily fix this by adding self-loops, that is an edge starting and ending on the same node; in this way, a node will become a neighbour of itself. Mathematically, self-loops are nothing but can be expressed by adding the identity matrix to the adjacency matrix.
2. Degree of the nodes lead to the values being scaled asymmetrically across the graph: In simple words, nodes that have a large number of neighbours (higher degree) will get much more input in the form of neighbourhood aggregation from the adjacent nodes and hence will have a larger value and vice versa may be true for nodes with smaller degrees having small values. This can lead to problems during the training of the network. To deal with the issue, we will be using normalisation, i.e., reduce all values in such a way that the values are on the same scale. Normalising $A$ such that all rows sum to one, i.e. $D^{−1}A$, where $D$ is the diagonal node degree matrix, gets rid of this problem. Multiplying with $D^{−1}A$ now corresponds to taking the average of neighboring node features. According to the authors, after observing empirical results, they suggest “In practice, dynamics get more interesting when we use symmetric normalisation, i.e. $\hat{D}^{-\frac{1}{2}}\hat{A}\hat{D}^{-\frac{1}{2}}$ (as this no longer amounts to mere averaging of neighbouring nodes).
After addressing the two problems stated above, the new propagation function $f$ is:$$f(H^{(l)}, A) = \sigma\left( \hat{D}^{-\frac{1}{2}}\hat{A}\hat{D}^{-\frac{1}{2}}H^{(l)}W^{(l)}\right)$$
where
- $\hat{A} = A + I$
- $I$ is the identity matrix
- $\hat{D}$ is the diagonal node degree matrix of $\hat{A}$.
Implementing GCNs from Scratch in PyTorch
We are now ready to put all of the tools together to deploy our very first fully-functional Graph Convolutional Network. In this tutorial, we will be training GCN on the ‘Zachary Karate Club Network’. We will be using the ‘Semi Supervised Graph Learning Model’ proposed in the paper by Thomas Kipf & Max Welling.
Zachary Karate Club
During the period from 1970-1972, Wayne W. Zachary observed the people belonging to a local karate club. He represented these people as nodes in a graph and added an edge between a pair of people if they interacted with each other. The result was the graph shown below.

During the study, an interesting event happened. A conflict arose between the administrator “John A” and instructor “Mr. Hi” (pseudonyms), which led to the split of the club into two. Half of the members formed a new club around Mr. Hi; members from the other part found a new instructor or gave up karate.
Using the graph that he had found earlier, he tried to predict which member will go to which half. And surprisingly he was able to predict the decision of all the members except for node 9 who went with Mr. Hi instead of John A.
Zachary used the maximum flow – minimum cut Ford–Fulkerson algorithm for this. We will be using a different algorithm today; hence it is not required to know about the Ford-Fulkerson algorithm.
Here we will be using the Semi-Supervised Graph Learning Method. Semi-Supervised means that we have labels for only some of the nodes, and we have to find the labels for other nodes. Like in this example we have the labels for only the nodes belonging to ‘John A’ and ‘Mr. Hi’, we have not been provided with labels for any other member, and we have to predict that only on the basis of the graph given to us.
Required Imports
In this post, we will be using PyTorch and Matplotlib.
|
|
The Convolutional Layer
First, we will be creating the GCNConv class, which will serve as the Layer creation class. Every instance of this class will be getting Adjacency Matrix as input and will be outputting ‘RELU(A_hat * X * W)’, which the Net class will use.
|
|
|
|
In this example, we have the label for admin(node 1) and instructor(node 34) so only these two contain the class label(0 and 1) all other are set to -1, which means that the predicted value of these nodes will be ignored in the computation of loss function.
X is the feature matrix. Since we don’t have any feature of each node, we will just be using the one-hot encoding corresponding to the index of the node.
Training
|
|

As you can see above, it has divided the data into two categories, and it is close to what happened to reality.
PyTorch Geometric Implementation
We also implemented GCNs using this great library PyTorch Geometric (PyG) with a super active maintainer Matthias Fey. PyG is specifically built for PyTorch lovers who need an easy, fast and simple way out to implement and test their work on various Graph Representation Learning papers.
You can find our implementation made using PyTorch Geometric in the following notebook GCN_PyG Notebook with GCN trained on a Citation Network, the Cora Dataset. Also all the code used in the blog along with IPython notebooks can be found at the github repository graph_nets.
References
We strongly recommend reading up these references as well to make your understanding solid.Also, remember we asked you to remember one thing? To answer that read up on this amazing blog which tries to understand if GCNs really are powerful as they claim to be. How powerful are Graph Convolutions?
-
Semi-Supervised Classification with Graph Convolutional Networks by Thomas Kipf and Max Welling
-
How to do Deep Learning on Graphs with Graph Convolutional Networks by Tobias Skovgaard Jepsen