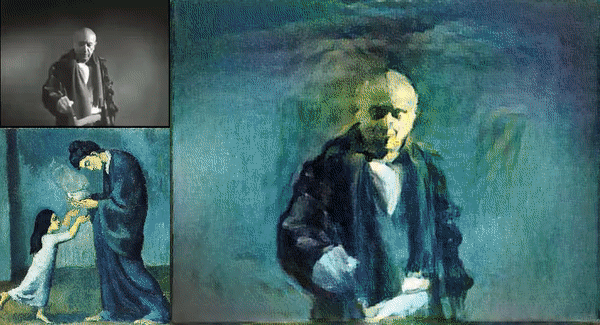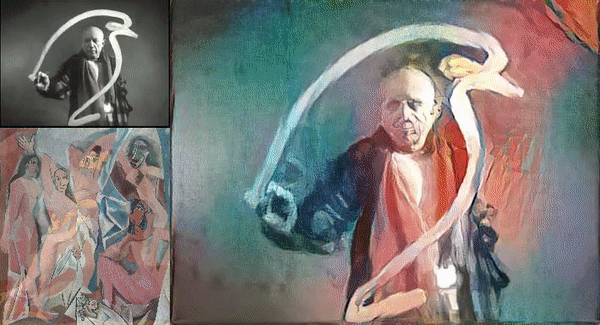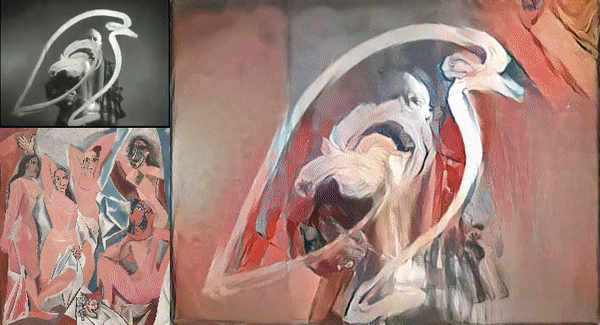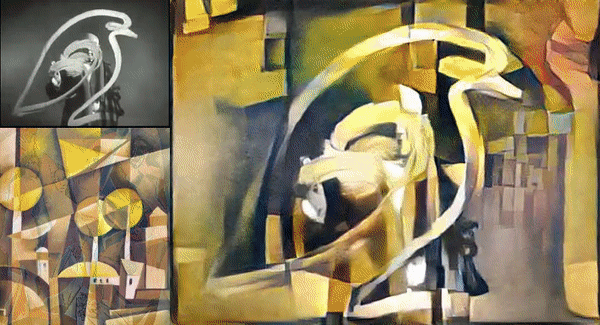
We all have used apps like Prisma and Lucid, but ever wondered how these things works? Like we give a photo from our camera roll and select a design to mix both the images and we get a new image which has the content of our input image and style of the design image. In the world of deep learning this is called style transfer.
Style transfer is the technique of recomposing images in the style of other images. It all started when Gatys et al. published an awesome paper on how it was actually possible to transfer artistic style from one painting to another picture using convolutional neural networks..
Here are some examples :

Convolutional Neural Network:
“Neural networks are everywhere. I do not expect that they will take away the bread of artists and designers, but it took my phone a minute to make quite interesting art work from several mediocre pictures.”
Convolutional Neural Networks (CNNs) are a category of Neural Network that have proven very effective in areas such as image recognition and classification. CNNs have been successful in computer vision related problems like identifying faces, objects and traffic signs apart from powering vision in robots and self driving cars.
CNN is shown to be able to well replicate and optimize these key steps in a unified framework and learn hierarchical representations directly from raw images.If we take a convolutional neural network that has already been trained to recognize objects within images then that network will have developed some internal independent representations of the content and style contained within a given image.
Here is an example of CNN hierarchy from VGG net where shallow layers learns low level features and as we go deeper into the network these convolutional layers are able to represent much larger scale features and thus have a higher-level representation of the image content.

VGG Network:
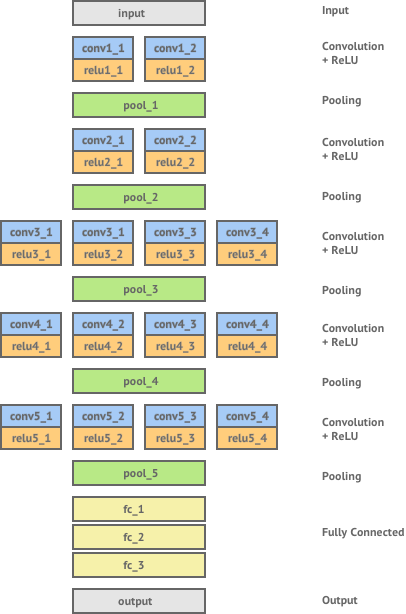
All winning architectures of ImageNet Large Scale Visual Recognition Challenge in recent years have been some form of convolutional neural network — with the most recent winners even being able to surpass human level performance!
In 2014, the winner of the ImageNet challenge was a network created by Visual Geometry Group (VGG) at Oxford University, achieving a classification error rate of only 7.0%. Gatys et. al use this network — which has been trained to be extremely effective at object recognition — as a basis for trying to extract content and style representations from images.
Content representation and loss:
We can construct images whose feature maps at a chosen convolution layer match the corresponding feature maps of a given content image. We expect the two images to contain the same content — but not necessarily the same texture and style.
Given a chosen content layer l, the content loss is defined as the Mean Squared Error between the feature map F of our content image C and the feature map P of our generated image Y.

When this content-loss is minimized, it means that the mixed-image has feature activation in the given layers that are very similar to the activation of the content-image. Depending on which layers we select, this should transfer the contours from the content-image to the mixed-image.
Style representation and loss:
We will do something similar for the style-layers, but now we want to measure which features in the style-layers activate simultaneously for the style-image, and then copy this activation-pattern to the mixed-image.
One way of doing this, is to calculate the Gram-matrix(a matrix comprising of correlated features) for the tensors output by the style-layers. The Gram-matrix is essentially just a matrix of dot-products for the vectors of the feature activations of a style-layer.
If an entry in the Gram-matrix has a value close to zero then it means the two features in the given layer do not activate simultaneously for the given style-image. And vice versa, if an entry in the Gram-matrix has a large value, then it means the two features do activate simultaneously for the given style-image. We will then try and create a mixed-image that replicates this activation pattern of the style-image.
If the feature map is a matrix F, then each entry in the Gram matrix G can be given by:

The loss function for style is quite similar to out content loss, except that we calculate the Mean Squared Error for the Gram-matrices instead of the raw tensor-outputs from the layers.
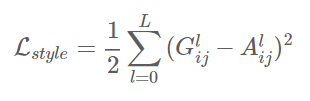
As with the content representation, if we had two images whose feature maps at a given layer produced the same Gram matrix we would expect both images to have the same style, but not necessarily the same content. Applying this to early layers in the network would capture some of the finer textures contained within the image whereas applying this to deeper layers would capture more higher-level elements of the image’s style. Gatys et. al found that the best results were achieved by taking a combination of shallow and deep layers as the style representation for an image.

We can see that the best results are achieved by a combination of many different layers from the network, which capture both the finer textures and the larger elements of the original image.
Optimizing loss function and styling the image:
Using a pre-trained neural network such as VGG-19, an input image (i.e. an image which provides the content), a style image (a painting with strong style elements) and a random image (output image), one could minimize the losses in the network such that the style loss (loss between the output image style and style of ‘style image’), content loss (loss between the content image and the output image) and the total variation loss (which ensured pixel wise smoothness) were at a minimum. In such cases, the output image generated from such a network, resembled the input image and had the stylist attributes of the style image.
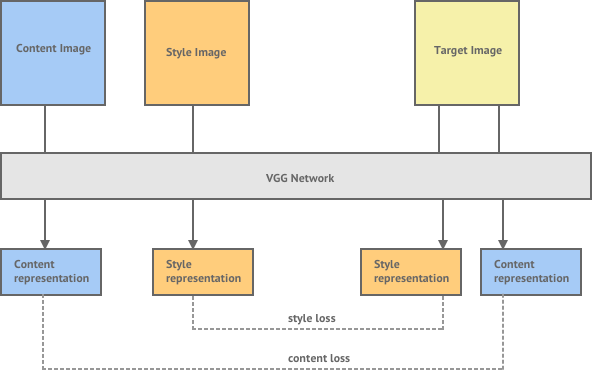
The total loss can then be written as a weighted sum of the both the style and content losses.

we will minimize our total loss by Adam optimizer. As our loss go down we will go close to our goal of producing a style transfer image Y.

Application of Style Transfer:
Audio/Music style transfers have already made some progress and several more use cases pertaining to unique human tasks like the style of playing chess etc. are also being explored, using more generalized frameworks of style transfer.
References
-
**Keras and Tensorflow implementation** Github repository of **DSG (IF YOU DON’T OPEN THIS, BLOG WAS NOT WORTH A READ)
Footnotes:
One suggestion is that do not miss out references, by reading them only you can understand algorithm properly.
Hit ❤ if this makes you little bit more intelligent.
Co-authors: Nishant Raj and Ashutosh Singh