Q Learning Agent to Play 2048
Implementation of Deep Q-network to play the game 2048 using Keras.
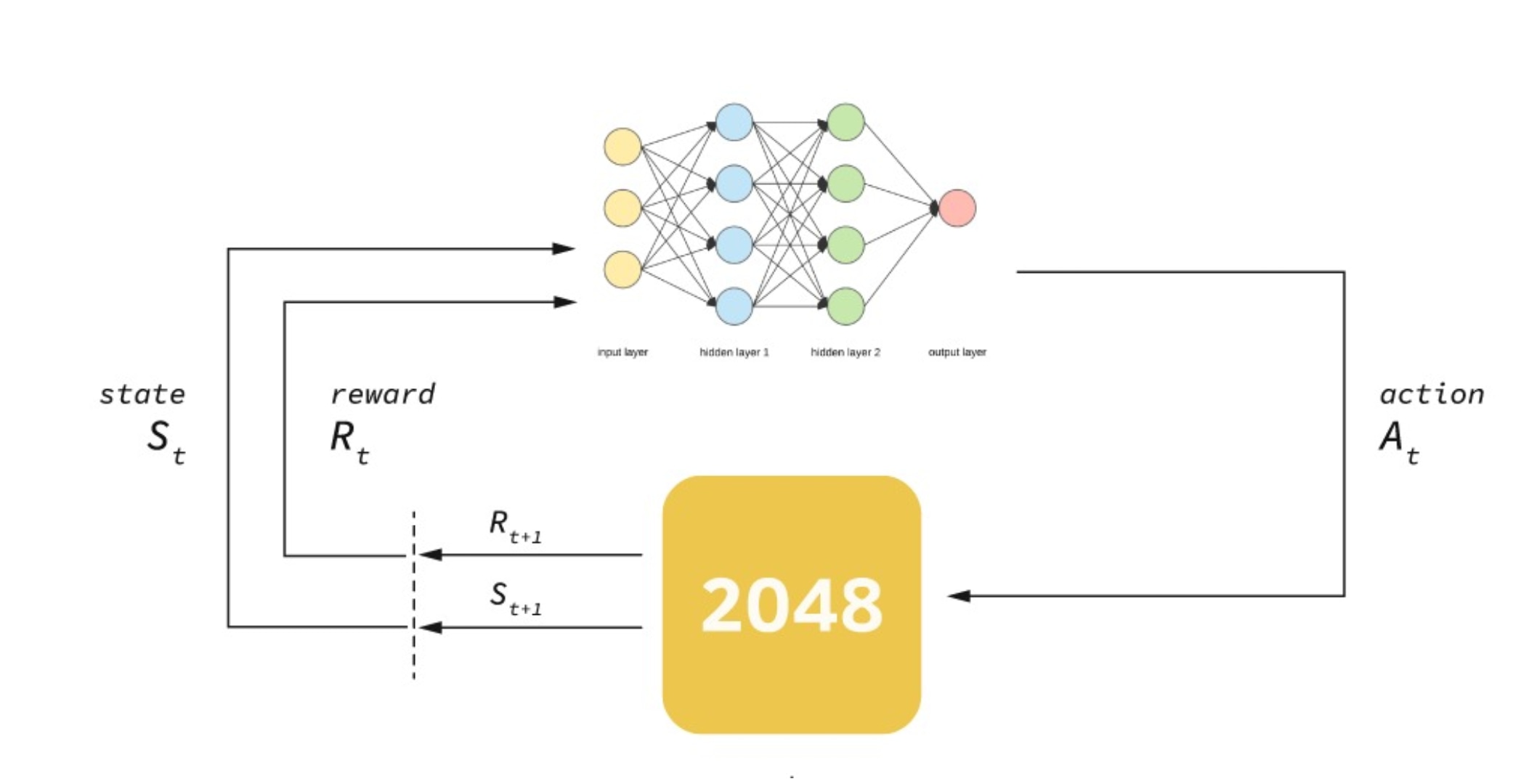
Project Description
For calculating the Q Values we used a Neural Network, rather than just showing the current state to the network, the next 4 possible states(left, right, up, down) were also shown. This intuition was inspired from Monte Carlo Tree Search estimation where game is played till the end to determine the Q-Values. Instead of using a normal Q Network, a Double Q Network was used one for predicting Q values and other for predicting actions. Training was done using the Bellman’s Equation. The policy used was Epsilon greedy, to allow exploration the value of epsilon was annealed down by 5%.