Convolutional Neural Network with TensorFlow Implementation
Saturday, Jun 17, 2017
Tags: Deep Learning, TensorFlow

When you hear about deep learning breaking a new technological barrier, Convolutional Neural Networks are involved most of the times.
Convolutional Neural Networks
Originally developed by Yann LeCun decades ago, better known as CNNs (ConvNets) are one of the state of the art, Artificial Neural Network design architecture, which has proven its effectiveness in areas such as image recognition and classification. The Basic Principle behind the working of CNN is the idea of Convolution, producing filtered Feature Maps stacked over each other.
A convolutional neural network consists of several layers. Implicit explanation about each of these layers is given below.
Convolution Layer (Conv Layer)
The Conv layer is the core building block of a Convolutional Neural Network. The primary purpose of Conv layer is to extract features from the input image.
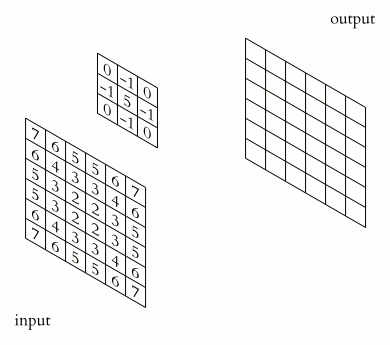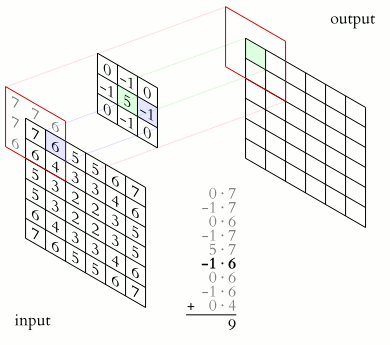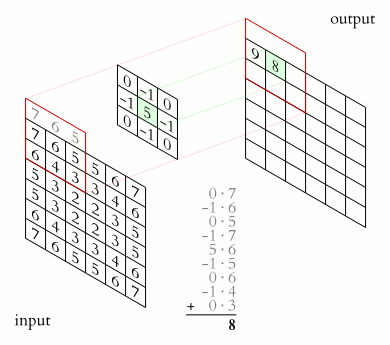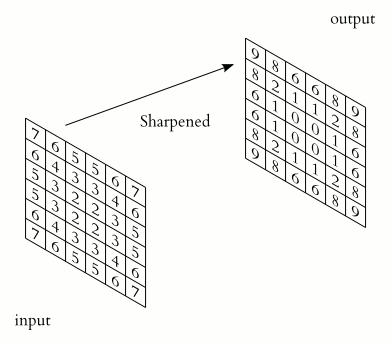
Convolution
The Conv Layer parameters consist of a set of learnable filters (kernels or feature detector). Filters are used for recognizing patterns throughout the entire input image. Convolution works by sliding the filter over the input image and along the way we take the dot product between the filter and chunks of the input image.
Pooling Layer (Sub-sampling or Down-sampling)
Pooling layer reduce the size of feature maps by using some functions to summarize sub-regions, such as taking the average or the maximum value. Pooling works by sliding a window across the input and feeding the content of the window to a pooling function.
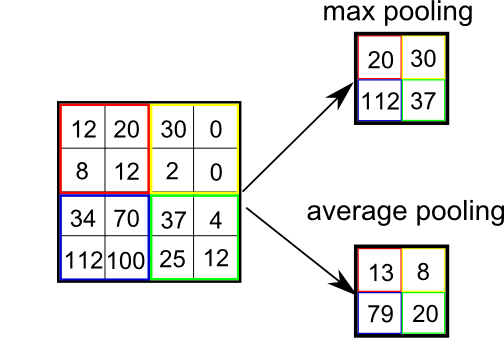
Max-Pooling and Average-Pooling
The purpose of pooling is to reduce the number of parameters in our network (hence called down-sampling) and to make learned features more robust by making it more invariant to scale and orientation changes.
3. ReLU Layer
ReLU stands for Rectified Linear Unit and is a non-linear operation. ReLU is an element wise operation (applied per pixel) and replaces all negative pixel values in the feature map by zero.
Output = Max(zero, Input)
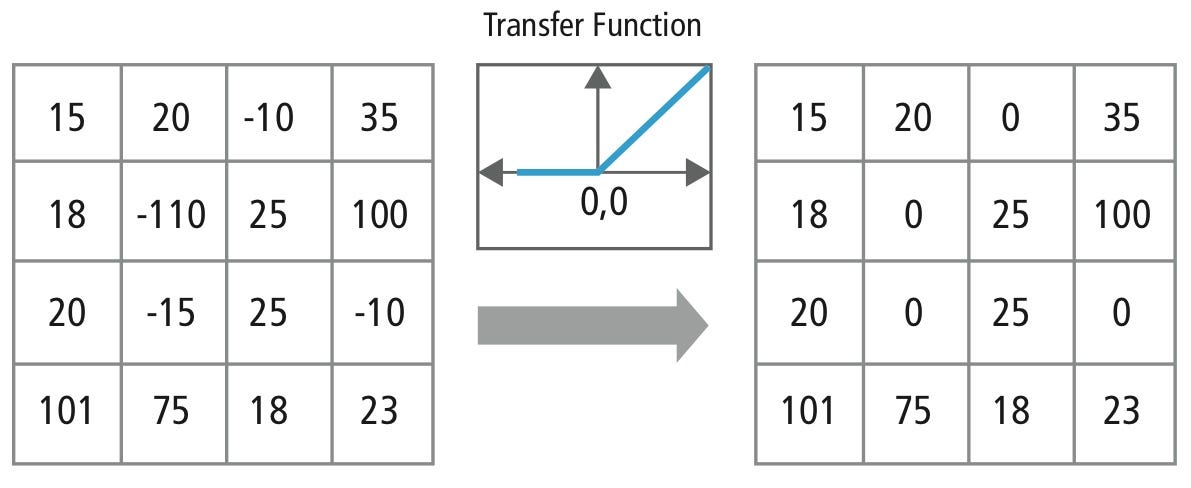
ReLU Layer
The purpose of ReLU is to introduce non-linearity in our ConvNet, since most of the real-world data we would want our ConvNet to learn would be non-linear.
Other non linear functions such as tanh or sigmoid can also be used instead of ReLU, but ReLU has been found to perform better in most cases.
4. Fully Connected Layer
The Fully Connected layer is configured exactly the way its name implies: it is fully connected with the output of the previous layer. A fully connected layer takes all neurons in the previous layer (be it fully connected, pooling, or convolutional) and connects it to every single neuron it has.
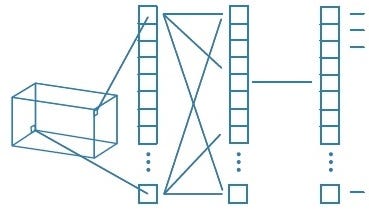
Fully Connected Layer
Adding a fully-connected layer is also a cheap way of learning non-linear combinations of these features. Most of the features learned from convolutional and pooling layers may be good, but combinations of those features might be even better.
TensorFlow
TensorFlow is an open source software library created by Google for numerical computation using data flow graphs.

Nodes in the graph represent mathematical operations, while the graph edges represent the multidimensional data arrays (tensors) that flow between them. This flexible architecture lets you deploy computation to one or more CPU’s or GPU’s in a desktop, server, or mobile device without rewriting code.
TensorFlow also includes TensorBoard, a data visualization toolkit.
Building a CNN in TensorFlow
Dataset
In this article, we will be using MNIST, a data-set of handwritten digits (The “hello world” of image recognition for machine learning and deep learning).
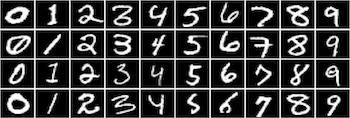
MNIST Sample Images
It is a digit recognition task. There are 10 digits (0 to 9) or 10 classes to predict. Each image is a 28 by 28 pixel square (784 pixels total). We’re given a total of 70,000 images.
Network Architecture
- Convolution, Filter shape:(5,5,6), Stride=1, Padding=’SAME’
- Max pooling (2x2), Window shape:(2,2), Stride=2, Padding=’Same’
- ReLU
- Convolution, Filter shape:(5,5,16), Stride=1, Padding=’SAME’
- Max pooling (2x2), Window shape:(2,2), Stride=2, Padding=’Same’
- ReLU
- Fully Connected Layer (128)
- ReLU
- Fully Connected Layer (10)
- Softmax
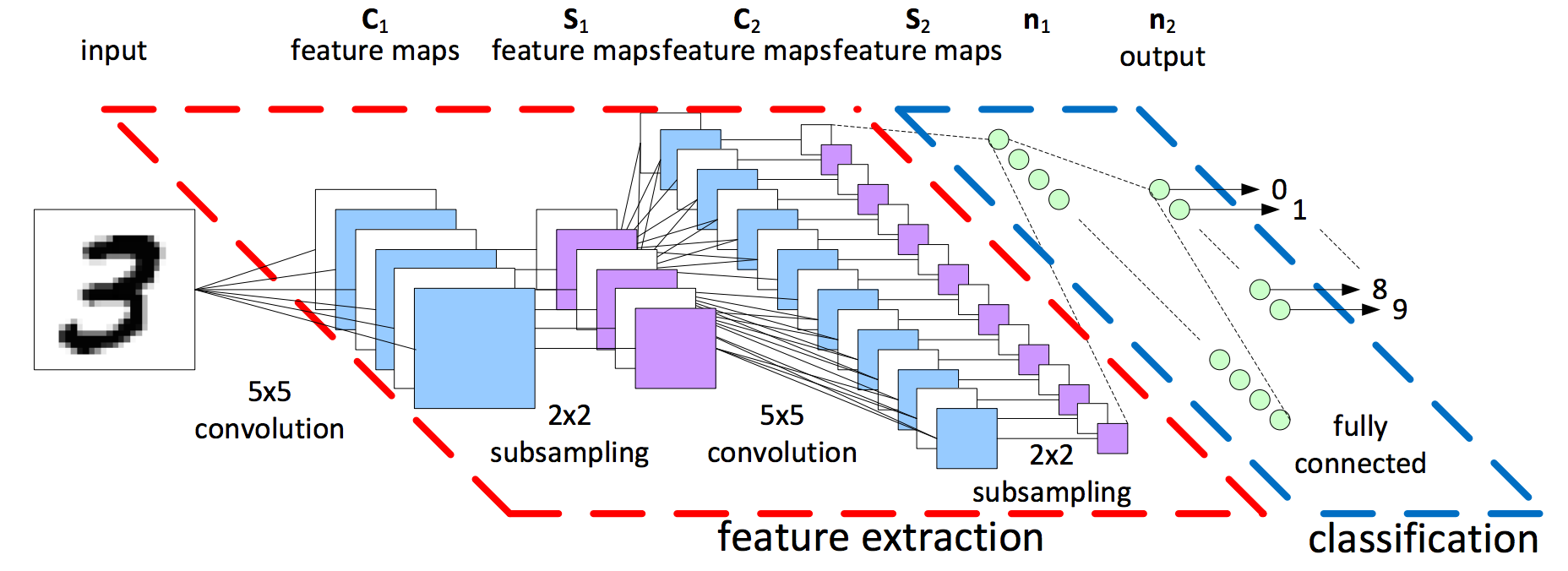
Architecture
Code
Loading
view rawConvolutional_Neural_Network-TensorFlow.ipynb hosted with ❤ by GitHub
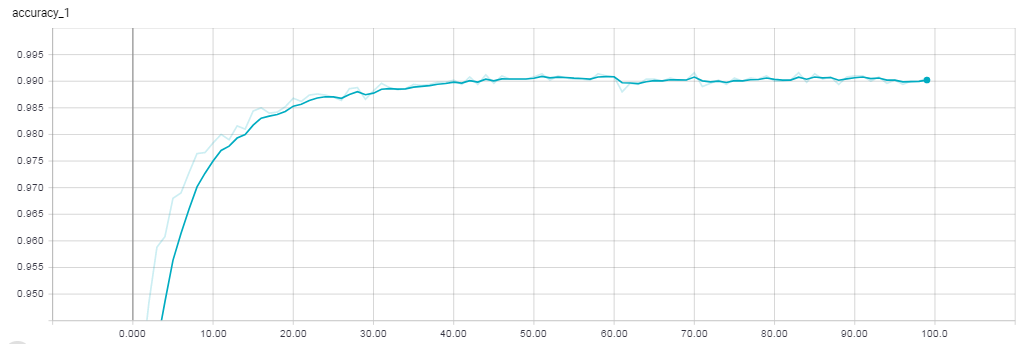
We can plot the validation accuracy and loss versus the number of epoch’s using TensorBoard :
- Validation Accuracy
- Validation Loss
With minimal efforts, we managed to reach an accuracy of 99% which is not that bad for a classification task with 10 labels. This result has been achieved without extensive optimization of the convolutional neural network’s parameters, and also without any form of regularization. To improve the performances, we could set up more complex model architectures so as to refine the feature extraction.
See the results of our Convolutional Neural Network on some validation examples:
MNIST Sample Classifications
Conclusion
Through this post, we were able to implement the simple Convolutional Neural Network architecture using the Python programming language and the TensorFlow library for deep learning. There are several details that are oversimplified / skipped but hopefully this post gave you some intuition of how it works.
Thanks for reading!
In case you have any doubts/feedback, kindly comment