GodNet: A Neural Network Which Can Predict Your Future?

“Have you ever questioned the nature of your reality, Dolores?” — Westworld.
“Are you living in a computer simulation?” — This was the title of a 2003 paper published by Nick Bostrom, a Swedish philosopher at the University of Oxford. Googling “Are you living in a computer simulation?” — amounts to around 150 million search results. And apart from bothering many scientists, philosophers, and people who have questioned the nature of their reality, this has been the idea behind many movies, novels, podcasts, and much more.
In this article, I would be writing a little bit about this notion of computer-simulated reality from an Artificial Intelligence perspective. How would the world change if in fact, it turned out that we are all just a part of a simulation? What is the nature of our reality?
To answer these questions, first, we must understand the most human-like thing that we have created: Artificial Intelligence (AI). With the recent advances in AI, it has been possible to generate music. We can generate faces of humans who don’t even exist. There are systems which (or who) can play Poker, Chess, and can defeat even the greatest players in the game of Go. And much more.
Most of these breakthroughs came due to a technique which is being heavily used these days to create intelligent systems: Neural Networks. And guess what, they’ve got names.
Though the idea of neural networks is quite old, we can say that it all started with LeNet (a pioneering network by Yann LeCun), a small neural network which could perform image classification. Later, an even ‘deeper’ architecture, InceptionNet, was proposed which could predict what’s in an image with even higher accuracy. Generative Adversarial Networks (GANs) can generate faces of people who don’t even exist. And much more. Seems like these neural networks are really good to learn a mapping from an input (x) to some output (y).
So, extrapolating on these achievements, can we make a neural network which takes the sequence of present video frames as input and can output the video frames of the future? Can Artificial Intelligence (AI) predict the future? Does there exist some ultimate neural network, GodNet, which is the most concise representation of our universe and the theory of everything?
In the rest of this article, we would start with understanding what a ‘function’ is. We would keep on adding blocks to our understanding of AI and finally discuss, whether such a _GodNet _can exist outside the realm of science-fiction.
What is a Function?
“The difference between the poet and the mathematician is that the poet tries to get his head into the heavens while the mathematician tries to get the heavens into his head.” — G.K. Chesterson
A function is a mathematical entity which maps an input to an output by performing some operations on it. Generally, if the function is called** f**, this relation is denoted by, y = f (x) (read f of x), the element x is the argument or input of the function, and y is the value of the function, the output.
A function can be as simple as: y = f (x) = 2x² + 3x + 1, which takes real numbers as input (say 5) and spits out an output ( f(5) = 66 in this case). To generate y, we had to perform certain operations on x as defined by the function f.
Or it can be as complex as a function, where the input x, is an image and the output y, is ‘cat’, denoting that there’s a cat in the image. But what exactly should be the design of the function f, so that it can predict what’s in an image? That’s where AI comes in.
What is Artificial Intelligence?
Let’s imagine a scenario. You are having a conversation with your boss, who has quite a big nose and an even bigger vocabulary. While talking, he said a word, ‘noctambulist’, which you have heard for the first time. Well, just like me, English is not your native language and you don’t want to look stupid in front of your boss. So you decided to understand what the word means through the context and kept talking to your boss. Since you are smart, after some time you figured out that a ‘noctambulist’ person is someone who walks in sleep.
Can we make machines do the same thing? It turns out, yes. A team of researchers led by Tomas Mikolov at Google developed a group of related models called Word2Vec which does something pretty similar. Using Word2Vec, a machine can tell what might ‘noctambulist’ mean.
Artificial Intelligence or AI, deals with the art and science of making machines which can do tasks which only “intelligent humans” are supposed to do. Like playing chess, driving a car and telling the meaning of a word just from the context.
We, humans, have designed many intelligent systems using different techniques. Libratus (or ‘Balanced’ in Latin), an AI system which can play Poker, uses techniques and algorithms from Game Theory. DeepMind’s AlphaGo, an AI system which defeated Lee Sedol in a game of Go, is based on Reinforcement Learning. However, most of the recent advances in AI have been accomplished with Deep Learning, and at the heart of Deep Learning is something known as a neural network.
What is a Neural Network?
Remember the simple function we talked about: y = f (x) = 2x² + 3x + 1. Here the input x goes through a transformation and produces y. Let’s call this one layer of computation. What if we apply some other transformation on this output y and convert it into some z. Thus the overall transformation that x went through to produce z is much more complex than the transformation required to produce y.
Neural Networks pretty much follow the same idea. Neural Networks are just a bunch of nodes (or neurons) connected layer by layer which define the transformation that the input would go through to produce the output. A specific connection (or network) of layers and nodes is called an Architecture.
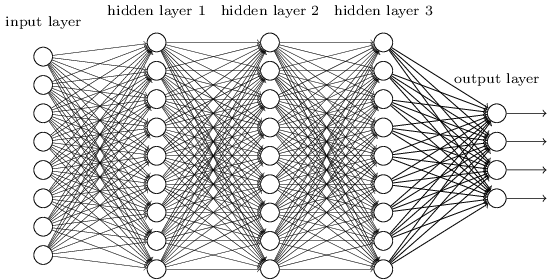 Each node has some ‘parameters’ associated with it which are used to perform the transformations. These parameters are learned using some past data (called training data) and a learning algorithm (like Gradient Descent). Just like you would adjust the pegs to tune the string of a guitar until you hit the perfect note, we adjust the ‘parameters’ of a neural network until it has learned how to perform the task that you want it to perform.
Each node has some ‘parameters’ associated with it which are used to perform the transformations. These parameters are learned using some past data (called training data) and a learning algorithm (like Gradient Descent). Just like you would adjust the pegs to tune the string of a guitar until you hit the perfect note, we adjust the ‘parameters’ of a neural network until it has learned how to perform the task that you want it to perform.
In case you have the curiosity and the time to learn more, I highly recommend you to watch this video by 3Blue1Brown.
Convolutional Neural Networks— CNNs
The above shown neural network is known as a ‘Multi-Layer Perceptron’. However, there are other variants of neural networks which are suited for specific tasks. Convolutional Neural Networks (CNNs) are one such class of neural networks which are most commonly applied to analyze visual imagery.
In fact, the recent surge of interest in AI began when AlexNet, a CNN designed by Alex Krizhevsky, won the 2012 ImageNet LSVRC-2012 competition. Since then, researchers have come up with more and more complex *architectures *like VGGNet, ResNet, GoogLeNet, U-Net etc.
CNNs work by extracting a more and more abstract representation of the features in an image by passing the image through convolutional layers. This representation is learned by adjusting the parameters associated with the layers such that it satisfies some given training data for the task.
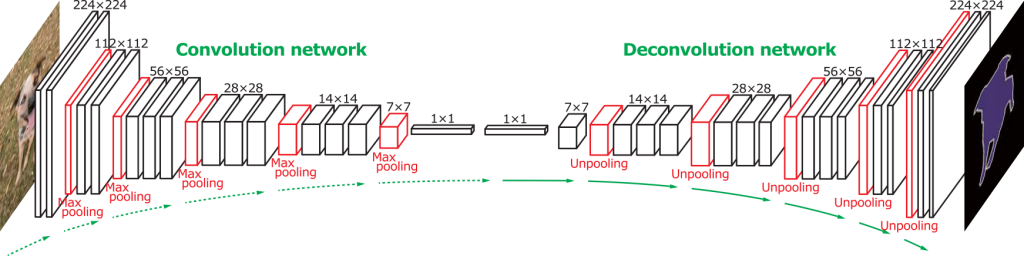 Though there’s much more to the story of CNNs, we’ll restrict ourselves here. In case you want to read more about them, check out this blog.
Though there’s much more to the story of CNNs, we’ll restrict ourselves here. In case you want to read more about them, check out this blog.
Generative Adversarial Networks (GANs)
Okay, so CNNs are cool. But when two networks start ‘competing’ with each other, things get even cooler. Generative adversarial networks (GANs) are deep neural net architectures comprised of two nets (networks), pitting one against the other.
Imagine a thief who is a not-so-good artist. He makes fake replicas of famous paintings (like Mona Lisa) and sells it to people. The town’s policeman suspects something wrong going on and decides to check every painting made by the thief. To earn more profit, the thief needs to create paintings which are almost like the original ones. To stop the thief, the police has to be good at discriminating real and fake artwork. If this battle between the thief and the police goes on for quite some time, eventually, the policeman would become a better and better discriminator and the thief would become pretty close to Pablo Picasso.
A GAN also consists of two networks: the generator (The thief) generates new instances of data, while the other, the discriminator (The police), evaluates them for authenticity (real or fake).
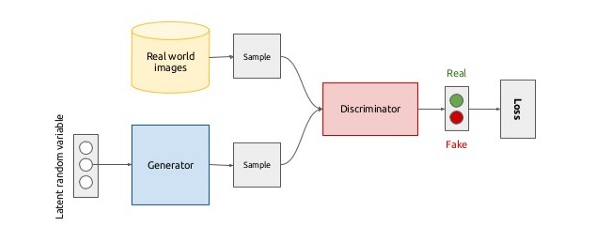 Both nets are trying to optimize a different and opposing objective function, just like in our thief-police example. As the discriminator changes its behavior, so does the generator, and vice versa. Eventually, we have a generator which can generate new data which looks authentic but isn’t.
Both nets are trying to optimize a different and opposing objective function, just like in our thief-police example. As the discriminator changes its behavior, so does the generator, and vice versa. Eventually, we have a generator which can generate new data which looks authentic but isn’t.
Referring to GANs, Facebook’s AI research director Yann LeCun called adversarial training “the most interesting idea in the last 10 years in Machine Learning.” For more about GANs, you might want to check out this video by ComputerPhile.
Into the Future: FutureGANs
In a 2018 paper, the authors introduced a GAN model, FutureGAN, that predicts future frames of a video sequence conditioned on a sequence of past frames. During training, the networks solely receive the raw pixel values as an input, without relying on additional constraints or dataset specific conditions. The FutureGAN model utilizes the training strategy of progressively growing GANs and extends it to the complex task of video prediction.
Predicting future frames of a video sequence (usually called Video Prediction) is complex. Like really complex. The authors of FutureGANs conducted experiments and tested FutureGAN on three datasets, the MovingMNIST dataset, the KTH Action dataset, and the Cityscapes dataset. And these datasets have video sequences much much simpler than a typical video sequence you would encounter in Nolan’s movies. Though FutureGANs achieved quite good results on these datasets, they would have a really hard time predicting the future video frames of a movie.
GodNet: The Theory of Everything?
Indeed neural networks have achieved massive success in Image Classification, but we might still be far far away from achieving the same success in Video Prediction.
However, let’s take it one step further. What if we somehow started collecting a video which contains everything that’s happening in the world or in the universe? A 360-degree sort of video. And what if we applied the same ideas of neural networks to predict the future video frames of that video? And what if we give it literally the present video frames as input? Would it produce future video frames?
Does there exist some ideal secret network: GodNet, which is still light-years ahead of our understanding? Is it even theoretically possible to find such a network? Is it possible to represent everything happening in the universe with just a bunch of nodes, layers, and parameters? A theory of everything?
What if we keep GodNet running and let it produce future video frames forever? And *what if the future video frames produced by the network indeed turned out to be your future? *Can we project the future video frame on some sort of 3-D screen and create a mini-simulation?
What if Your ‘Existence’ & ‘Free Will’ is a Lie?
Though a system which can predict your future seems like it only exists in the realm of science fiction. And no doubt, we are still far far away from it.
But, what if one day we found those magical parameters of that magical architecture which can predict your future. A day when you found out that your infinite universe was nothing more than a neural network’s output being projected on a 3-D screen. What your reaction would be? What would you say about your free will?
I was just reading ‘Sapiens’, by Yuval Noah Harari, and he mentioned something interesting about chaos. There are two main classifications of chaos.
-
First-Order Chaos doesn’t respond to prediction. If you predict the weather to some level of accuracy, that prediction will hold because the weather doesn’t adjust based on the prediction itself.
-
Second-Order Chaos is infinitely less predictable because it does respond to prediction. Examples include things like stocks and politics.
Would you be able to respond to the predictions made by GodNet? Is our life an example of first or second order chaos?
There might come a time when we’ll have answers to all these questions. But that future is far. And the questions still remain unanswered. Are we living in a simulation? Is there really anything like free will? Do are decisions really matter?
Finally, by no means, I am an expert in Machine Learning, AI, Philosophy, or the Simulation Hypothesis. I would very much love to hear your suggestions, ideas, and thoughts on this subject.
Let’s finish this article with the same question that we started with. The question which Bernard keeps asking Dolores throughout almost the entire season of Westworld.